Apache Spark, cái tên nghe có thể lạ lẫm bởi đa số bạn. Tuy nhiên với dân khoa học máy tính (data science) thì đây là một nền tảng không thể thiếu. Đặc biệt là những bạn đang làm việc trong ngành BigData xử lý các dữ liệu cực lớn. Bài viết này 7Host sẽ hướng dẫn các bạn cài đặt Apache Spark trên hệ điều hành Ubuntu Server 20.04 LTS mới nhất. Bài viết sử dụng VPS để cài đặt và tất nhiên các bạn cũng có thể tự cài đặt trên máy ảo tại nhà.
Tham khảo thêm: Hướng dẫn cài đặt Ubuntu Server 20.04 LTS mới nhất
1. Chuẩn bị
Đầu tiên cần kiểm tra lại hostname và file hosts trên máy chủ đã trùng khớp chưa ? Nếu hai thông số này không giống nhau sẽ khiến việc khởi động Apache Spark bị lỗi ngay lập tức.
Lưu ý: Trong bài viết này toàn bộ thao tác đều được 7Host sử dụng với user “root“. Nếu các bạn chạy user khác thì cần phải thêm “sudo” trước mỗi lệnh nhé.
root@ubuntu-vps:~# cat /etc/hosts 127.0.0.1 localhost 127.0.1.1 ubuntu-vps
Nếu hai thông số chưa trùng nhau thì các bạn dùng editor như nano, vim, vi…để chỉnh sửa lại nhé. Sau đó thực hiện khởi động lại máy chủ để cấu hình được áp dụng.
Tiếp đến tiến hành update các gói (package) có trong Ubuntu để đảm bảo là bản mới nhất. Các bạn lần lượt chạy hai lệnh sau đây:
root@ubuntu-vps:~# apt update root@ubuntu-vps:~# apt -y upgrade
Ngoài ra để chạy được Spark thì cũng cần đến Java nên các bạn tiến hành cài java bằng duy nhất lệnh sau:
root@ubuntu-vps:~# apt install default-jdk -y
Kiểm tra java đã cài đặt thành công hay chưa ?
root@ubuntu-vps:~# java -version openjdk version "11.0.11" 2021-04-20 OpenJDK Runtime Environment (build 11.0.11+9-Ubuntu-0ubuntu2.20.04) OpenJDK 64-Bit Server VM (build 11.0.11+9-Ubuntu-0ubuntu2.20.04, mixed mode, sharing)
Thông tin hiển thị bạn đã cài java phiên bản “11.0.11”. Như vậy là bạn đã hoàn thành các thiết lập cần thiết.
2. Cài đặt Apache Spark
Việc cài đặt Spark rất đơn giản thông qua vài bước là có thể sử dụng ngay.
- Bước 1: Download source mới nhất của Spark từ trang chủ tại đây: Download | Apache Spark
root@ubuntu-vps:~# wget https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
- Bước 2: Tiến hành giải nén file vừa tải về
root@ubuntu-vps:~# tar xvf spark-3.1.2-bin-hadoop3.2.tgz
- Bước 3: Chuyển thư mục vừa giải nén vào thư mục cố định đồng thời đổi tên thư mục thành “spark”.
root@ubuntu-vps:~# mv spark-3.1.2-bin-hadoop3.2 /opt/spark
- Bước 4: Khai báo biến môi trường để Spark có thể hoạt động. Mở file “~/.profile”.
root@ubuntu-vps:~# nano ~/.profile
Thêm vào nội dung sau và save lại.
export SPARK_HOME=/opt/spark export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin export PYSPARK_PYTHON=/usr/bin/python3
- Bước 5: Kích hoạt biến môi trường.
root@ubuntu-vps:~# source ~/.profile
Sau bước này các bạn đã có được Apache Spark trên Ubuntu rồi đấy. Tiến hành khởi động dịch vụ bằng lệnh sau:
root@ubuntu-vps:~# start-master.sh
Trong đó: Nếu máy chủ này chạy độc lập hoặc là máy chủ đầu tiên chạy Spark thì các bạn dùng script “start-master.sh” như trên. Nếu máy chủ từ thứ hai trở đi gắn vào để tạo thành “cluster” thì các bạn chọn “start-slave.sh”
Kiểm tra lại Spark đã lắng nghe trên port mặt định là 7077 hay chưa ?
root@ubuntu-vps:~# netstat -nltp Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 582/sshd: /usr/sbin tcp6 0 0 :::8080 :::* LISTEN 827/java tcp6 0 0 :::22 :::* LISTEN 582/sshd: /usr/sbin tcp6 0 0 127.0.1.1:7077 :::* LISTEN 827/java
Trong đó port 8080 là WebUI dùng để theo dõi tình trạng hoạt động cũng như các “slave” đang gắn vào “cluster” này.
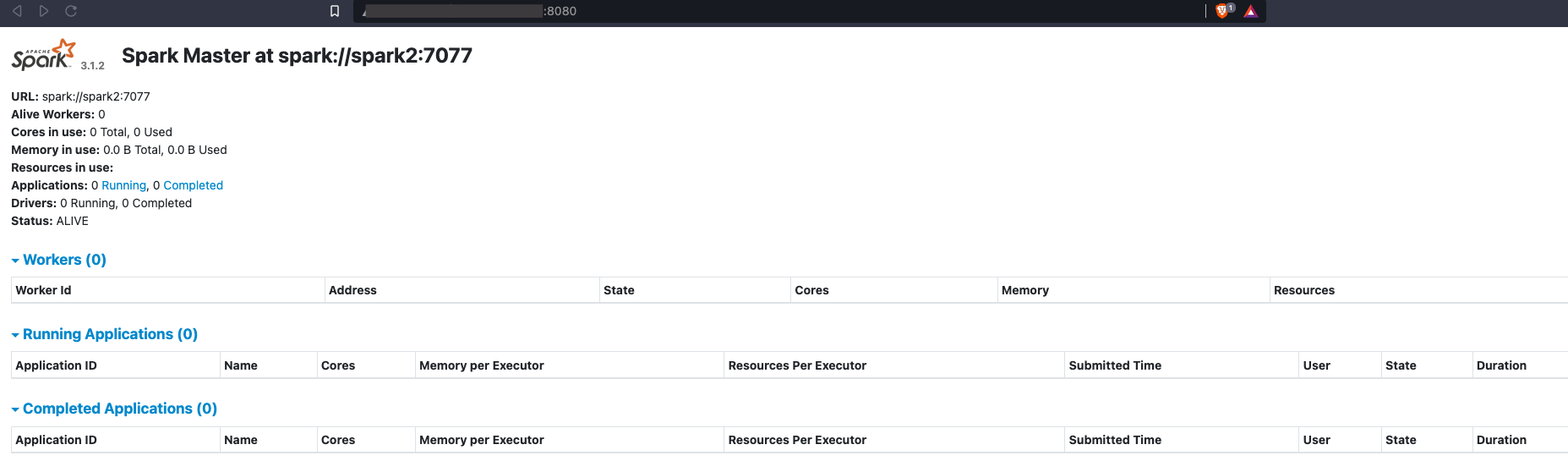
4. Tùy chọn thêm với PySpark
Mặc định Spark đi kèm với ngôn ngữ lập trình Scala. Nếu bạn đã quen với Python thì cần phải cài thêm gói “PySpark” để sử dụng Spark với ngôn ngữ Python.
root@ubuntu-vps:~# apt install python3-pip root@ubuntu-vps:~# pip install pyspark
Tiến hành kiểm tra lại Python đã kết nối được Spark chưa ?
root@spark2:~# pyspark
Python 3.8.10 (default, Jun 2 2021, 10:49:15)
[GCC 9.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
21/08/21 11:46:40 WARN Utils: Your hostname, spark2 resolves to a loopback address: 127.0.1.1; using 103.159.52.114 instead (on interface eth0)
21/08/21 11:46:40 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.12-3.1.2.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
21/08/21 11:46:41 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Python version 3.8.10 (default, Jun 2 2021 10:49:15)
Spark context Web UI available at http://103.159.52.114:4040
Spark context available as 'sc' (master = local[*], app id = local-1629539204439).
SparkSession available as 'spark'.
>>>
5. Tổng kết
Như vậy là quá trình cài đặt Apache Spark đi kèm với Python trên Ubuntu Server 20.04 LTS đã hoàn tất. Nếu trong quá trình cài đặt gặp phải khó khăn các bạn đừng ngần ngại gửi email về [email protected] để được 7Host hỗ trợ cho các bạn nhé.
Chúc các bạn thành công!



